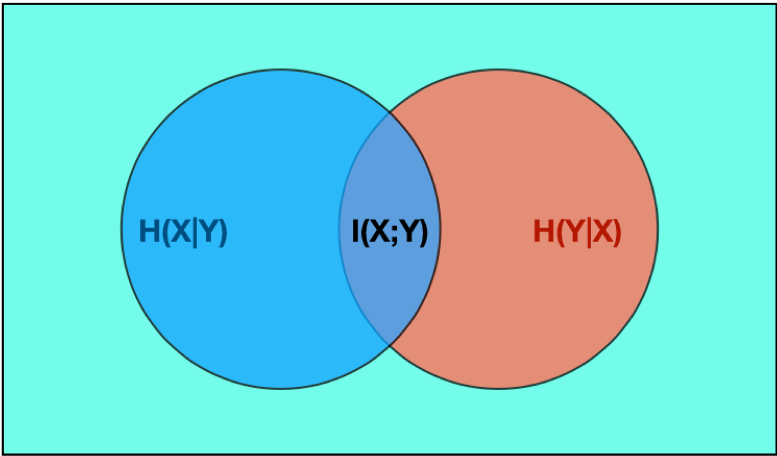
Infotheory
A C++/Python package for information theoretic analysis.
Expertise in 2D and 3D Computer Vision, with experience leading projects involving classical and deep learning approaches. Led teams to develop products in this space from conception, research all the way to deployment and support. Current role also includes creating technical roadmaps and creating the vision for the CV/ML team. I received my Ph.D. in Cognitive Science, with a minor in Computer Science in May 2020 from Indiana University, Bloomington under the mentorship of Dr. Eduardo Izquierdo.
Areas of research interest: 2D/3D Computer Vision, Robotics, Reinforcement Learning, Computational Neuroscience, Evolutionary Robotics, Information Theory, Complex Systems, Dynamical Systems Theory, Artificial Life.
Jun 2023 - Present
Feb 2022 - Jun 2023
June 2020 - Feb 2022
Summer 2018
2015 - 2020
2015
2015
2011 - 2012
2011
| "Machine learning logic-based adjustment techniques for robots." Lonsberry, Alexander, Andrew Lonsberry, Nima Ajam Gard, Madhavun Candadai Vasu, and Eric Schwenker. U.S. Patent Application 18/056,443. |
| "Autonomous Welding Robots." Lonsberry, Alexander, Andrew Lonsberry, Nima Ajam Gard, Colin Bunker, Fabian Benitez Quiroz, Madhavun Candadai Vasu. U.S. Patent Application US11648683B2. |
| [Patent pending] Title: Autonomous Assembly Robots. Type of application: US non-provisional. |
| [4 more patents filed] |
See Google Scholar or resume for an updated list of papers, talks and posters.
| Candadai, Madhavun, and Eduardo J. Izquierdo. "Sources of predictive information in dynamical neural networks." Scientific reports 10.1 (2020): 1-12. [pdf] |
| Candadai, Madhavun "Information theoretic analysis of computational models as a tool to understand the neural basis of behaviors" submitted to arxiv [pdf] |
| Benson, Lauren V., Madhavun Candadai, and Eduardo J. Izquierdo. "Neural reuse in multifunctional neural networks for control tasks." Artificial Life Conference Proceedings. One Rogers Street, Cambridge, MA 02142-1209 USA journals-info@ mit. edu: MIT Press, 2020. [pdf] |
| Candadai, Madhavun, Matthew Setzler, Eduardo J. Izquierdo, and Tom Froese. "Embodied dyadic interaction increases complexity of neural dynamics: A minimal agent-based simulation model." Frontiers in Psychology 10 (2019): 540. [pdf] |
| Vasu, Madhavun Candadai, and Eduardo J. Izquierdo. "Multifunctionality in embodied agents: Three levels of neural reuse." arXiv preprint arXiv:1802.03891 (2018). Proceedings of the 40th Cognitive Science Conference, 2018. [pdf] |
| Vasu, Madhavun Candadai , and Eduardo J. Izquierdo. "Information Bottleneck in Control Tasks with Recurrent Spiking Neural Networks". International Conference on Artificial Neural Networks. (ICANN) Springer, Cham, 2017. [pdf] |
| Vasu, Madhavun Candadai , and Eduardo J. Izquierdo. "Evolution and Analysis of Embodied Spiking Neural Networks Reveals Task-Specific Clusters of Effective Networks." In Proceedings of Genetic and Evolutionary Computing Conference, pp. 75-82. GECCO, 2017. [pdf] Nominated for Best Student Paper, 2017, by International Society for Artificial Life: Student Chapter |
| Leite, Abe, Madhavun Candadai, and Eduardo J. Izquierdo. "Reinforcement learning beyond the Bellman equation: Exploring critic objectives using evolution." Artificial Life Conference Proceedings. One Rogers Street, Cambridge, MA 02142-1209 USA journals-info@ mit. edu: MIT Press, 2020. [pdf] |
| Todd, Graham, Madhavun Candadai, and Eduardo J. Izquierdo. "Interaction between evolution and learning in nk fitness landscapes." Artificial Life Conference Proceedings. One Rogers Street, Cambridge, MA 02142-1209 USA journals-info@ mit. edu: MIT Press, 2020. [pdf] |
| Dwiel, Zach*, Madhavun Candadai*, Mariano J. Phielipp. (2019, November). On Training Flexible Robots using Deep Reinforcement Learning. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE. (Accepted) [pdf] (*equal contribution) |
| Dwiel, Zach, Madhavun Candadai, Mariano J. Phielipp, Arjun K. Bansal. "Hierarchical policy learning is sensitive to goal space design". In Task-Agnostic Reinforcement Learning Workshop (TARL), of International Conference on Learning Representations (ICLR), 2019. [pdf] |
| Candadai, Madhavun, Aashay Vanarase, Mei Mei, and Ali A. Minai. "ANSWER: An unsupervised attractor network method for detecting salient words in text corpora." In International Joint Conference on Neural Networks 2015, pp. 1-8. IEEE, 2015. [pdf] |
| Candadai, M., & Izquierdo, E. J. (2019). infotheory: A C++/Python package for multivariate information theoretic analysis. arXiv preprint arXiv:1907.02339. [pdf] |
| Candadai, M. (2020). Bits from Behaviors: Understanding Function Using Information in Embedded, Embodied, and Dynamical Neural Networks (Doctoral dissertation, Indiana University). [pdf] |
| Candadai Vasu, M. (2015). ANSWER: A Cognitively-Inspired System for the Unsupervised Detection of Semantically Salient Words in Texts (Master's thesis, University of Cincinnati). [pdf] |
A C++/Python package for information theoretic analysis.
Numpy implementations of backprop, sofm, ....
Javascript simulation of a Turing Machine.
Python package for evolutionary search using Multiprocessing
Python package for easily building and simulating CTRNNs

A generative finite state machine model for Indian carnatic music. Blog